"LEG Processor for Education" at EWME 2016
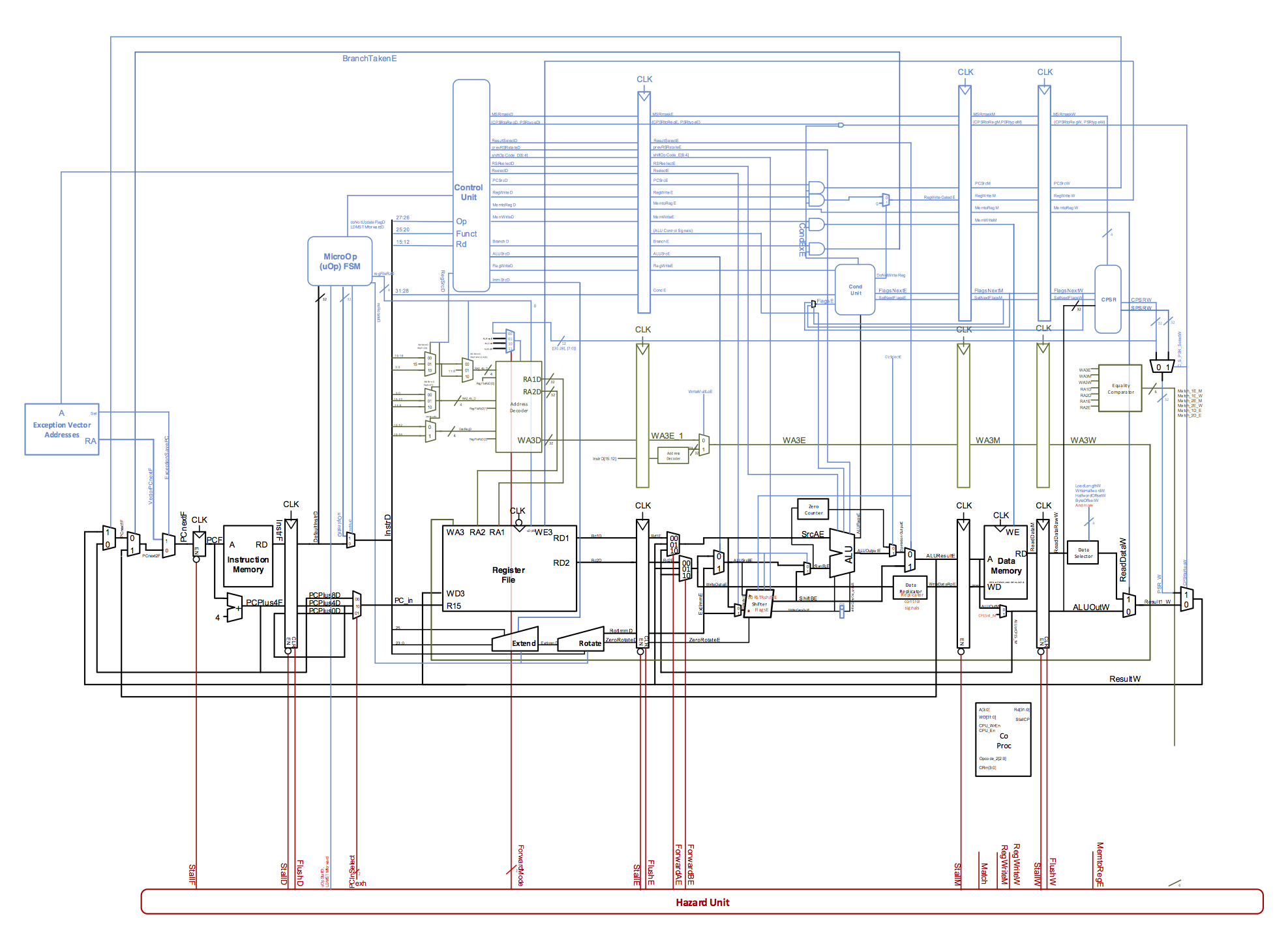
Last semester, I was part of the Clay Wolkin Fellowship at Harvey Mudd. The fellowship consists of a group of students (mostly Engineering majors, but some CS also) who work on interesting electrical-engineering-focused projects. The project I worked on was the "LEG Processor", an open-source pipelined processor that implements the ARMv5 instruction set and can boot the Linux kernel (3.19) in simulation. We recently published a paper describing our work in the European Workshop for Microelectronics! You can read the paper here. Or read on for a high-level overview of the work I did on the project.
First, a little background on processors. Processors work on machine code, the lowest level representation of the instructions for a computer. Machine code is basically just binary data with a specific structure, encoding a sequence of instructions. These instructions can manipulate the internal state of the processor in a few ways:
- Instructions can load values into registers, which are essentially a set of finitely many fixed-size variables.
- Instructions can perform math on registers.
- Instructions can save and load data from memory addresses.
- Instructions can change the program counter, which points to the next instruction to execute, and thus make the program jump to a different sequence of instructions (used to implement loops and branches).
Conceptually, to the programmer, a processor executes machine instructions in sequence. For instance, if you wanted to add two numbers, you might have assembly code like
MOV R0, #4 MOV R1, #10 ADD R0, R0, R1 ; after this R0 has value 14
and the processor would load 4 into R0, 10 into R1, and then add them together into R0. When executing each instruction, this conceptual processor goes through five main stages:
- FETCH: Read the program counter, and fetch the next instruction from memory.
- DECODE: Look at the machine code that was just loaded, and determine what action to take
- EXECUTE: Perform any necessary processing on the registers (i.e. do math) and temporarily store the results
- MEMORY: Load or store values into memory
- WRITEBACK: Update the registers with the new values
The reality of processors, however, is a bit more complicated. In order to speed up computation, modern processors often execute multiple instructions at the same time. This is called "instruction pipelining". An example of how this might work would be:
- First, fetch the first instruction (
MOV R0, #4) from memory. - Decode the first instruction (ok, we want to
MOVthe value 4 intoR0). At the same time, fetch the next instruction (MOV R1, #10). - Execute the first instruction (load 4 into temporary storage), decode the second (ok, we want to
MOVthe value 10 intoR1), fetch the third (ADD R0, R0, R1). - Do memory for first instruction (nothing to do here), execute the second (load 10 into temporary storage), decode the third (ok, we want to
ADDtogetherR0andR1and store result inR0) - Writeback first instruction (now
R0holds 4), do memory for second (nothing to do), execute the third (addR0, which has 4, withR1, which has 0 to start with but we are holding 10 in temporary storage so we should use that instead, to get 14, which we put in temporary storage) - Writeback second (now
R1holds 10), do memory for third (nothing to do) - Writeback third (now
R0holds 14)
An important thing to notice is that even though multiple instructions are executing at the same time, the processor must behave as if it were executing them sequentially. So at step 5, even though we haven't updated R1's value yet, we need to forward the temporary value back to the EXECUTE stage to make sure we get the right value. This also leads to some other complex situations. For instance, if we want to load a register from memory and then do math with it, we have to wait for the value to be ready before we can do the add. This is called a stall. Another problem is that if we encounter a conditional branch (i.e. a low-level if statement), the processor doesn't know which part to execute next, so it makes a guess. If it turns out that it guessed wrong, by the time it figures that out it will have started executing those wrong instructions. The processor has to throw out that old data, known as a flush.
You can probably see why implementing a processor, especially a pipelined one, from scratch is a very complex process. Naturally, then, there will be bugs. That's where I came in. My part of the project was building a flexible testing framework that would allow us to ensure that our processor was behaving correctly.
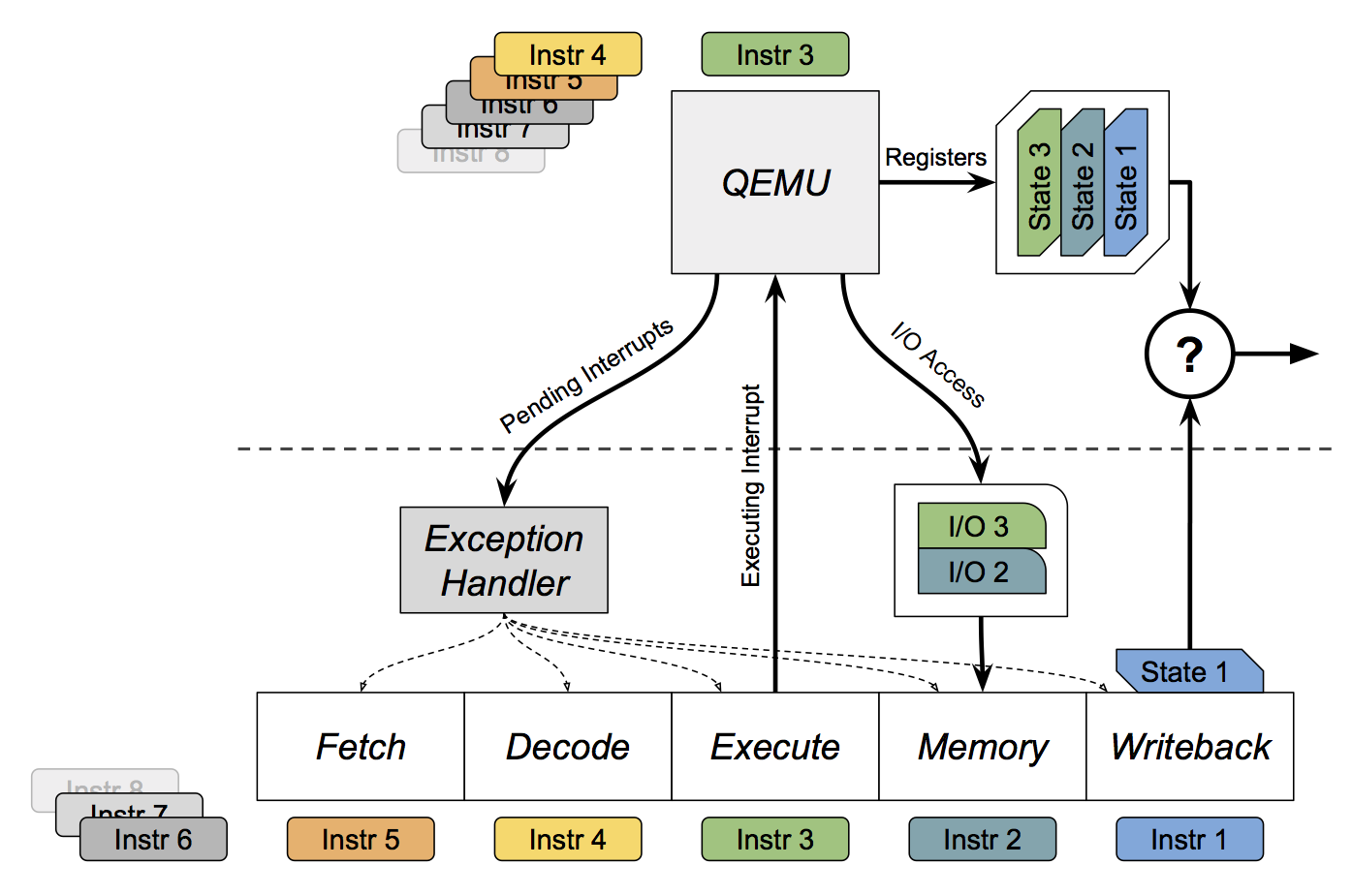
To verify the correctness of our processor, we decided to compare it to a reference implementation and ensure that the two implementations stayed in sync. We ended up using the QEMU emulator as our reference implementation. The overall process ended up looking a bit like this:
- The user starts GDB with a specific set of command line arguments.
- Based on those command line arguments, GDB loads a Python script, using its embedded Python interpreter.
- The python script starts (a custom version of) QEMU and attaches GDB to the emulated processor.
- The python script adds some extra commands to GDB, which are displayed to the user.
- The user uses one of those commands to start a debugging session.
- The python script uses some customized hooks into QEMU to save out the entire state of the QEMU processor.
- The python script starts up ModelSim, which is used to simulate our LEG processor, and passes the path to the saved state.
- A ModelSim script initializes the LEG processor and loads up the saved state.
- In a loop, the python script tells GDB and ModelSim to step through the execution of a program, one instruction at a time. After each instruction, the script checks all of the registers of both implementations to ensure that they match. If not, we have found a bug in our processor!
There are a few complications to this process, however. In particular, running a complex program (such as the Linux kernel boot process) may involve nondeterministic events. Two types of these events are IO accesses and interrupts.
IO accesses occur when the processor attempts to interface with a peripheral, such as a keyboard, mouse, or timer. Since we cannot predict what the state of that peripheral will be, this may break the lockstep and introduce differences in the processor state. To circumvent this, I implemented an "IO shim" for the LEG processor. Whenever the QEMU processor accesses IO, we detect the event and store the address accessed and the value read into a queue. Then, when the LEG processor attempts to access that same address, we simply substitute the value from the queue instead of actually attempting to access a peripheral.
Interrupts occur when some peripheral attempts to send information to the processor. For instance, the processor may ask a timer to notify it after some delay. After that delay occurs, the timer will send an interrupt to the processor, to tell it to stop what it is currently doing and handle the notification. Interrupts are very timing-sensitive, and can trigger at any time.
Furthermore, interrupt handling is made even more complex because of the pipelined nature of the processor. Pipelining prevents the LEG processor from immediately handling an interrupt; it must first finish handling the currently running instructions, and clear its state. QEMU, on the other hand, will trigger the interrupt immediately. This makes it difficult to keep the implementations in sync.
To handle interrupts intelligently, the script starts by disabling interrupt handling in QEMU. Whenever QEMU receives an interrupt, it instead just forwards the interrupt to the LEG processor. The script then waits until the LEG processor actually begins processing the interrupt. At that point, interrupts are re-enabled in QEMU, and both processors perform the interrupt in sync.
Here's a diagram of how the two processor implementations and the testing framework interact:
For more details, you can read the paper (although you may need an IEEE subscription to see it). Soon, the actual processor details should also become available for viewing, but it doesn't appear to be up yet.
In somewhat related news, I've written a paper describing my work with polyphonic music modeling, and am currently attempting to get it published. Hopefully relatively soon I'll be able to say I have two different publications!